What Is RAG And Why Do You Need It
Retrieval–Augmented Generation (RAG) is an advanced technique that supercharges large language models (LLMs) by connecting them to real–time, external data sources. Instead of relying solely on static, pre–trained knowledge, a RAG–enabled searches your proprietary data to fetch relevant information before generating a response. This approach ensures that answers are not only accurate, but also up–to–date and tailored to your business context – something that generic chatbots simply can't deliver.
Here is the typical flow of a RAG system:
- Retrieval When a user submits a query, the system searches designated data source that include your company data to extract the most relevant information.
- Augmentation This retrieved content is fed into AI model, supplementing its existing knowledge with domain-specific information.
- Generation The LLM creates a natural-language response based on the retrieved and internal knowledge, producing highly contextual and trustworthy results.
RAG is the key to building AI assistants that truly understand your business, answer complex questions accurately, and and deliver personalized support to your internal teams and customers. You need RAG to ensure that your natural language knowledge bases are built on your unique business data. Custom RAG solutions go beyond generic Q&A to deliver intelligent assistants that understand your operations, policies, and workflows. RAG systems reduce LLM hallucinations (confident, but incorrect answers), increase trust, and enable truly useful automation across customer support, employee onboarding, IT help desks, compliance, and operations. In short, if you want an AI system that speaks your language and knows your content, RAG is how you get there.
Why "Good Enough" Chatbots Are No Longer Enough
A lot of companies launched AI chatbots for FAQ pages in 2020. These chatbots answered common questions and deflected a fraction of tech support tickets, but they also hallucinated, contradicted policy updates, and left frustrated customers hunting for a human. Meanwhile, generative AI sprinted ahead. Today, Custom RAG Solutions — systems that blend large language models (LLM) with real-time retrieval from your proprietary data — are transforming customer support, internal knowledge bases and employee onboarding. Gartner predicts that by 2026, retrieval-augmented generation will power 40% of enterprise search and knowledge management workloads.
The promise is clear: context-aware answers, instant updates, regulatory compliance, and measurable ROI. Here we provide a proven framework: strategy, architecture, implementation, and scale, to help you move beyond generic chatbots that lack company-specific knowledge and deliver unreliable responses. In under 2 months, you can launch business-critical Custom RAG Solution that understands your company's data, provide accurate answers, and deliver real results. RAG solutions ensure that employees and customers get the information they need fast, without being misled by generic LLMs or forced to track down a human.
Challenges and Limitations of Generic AI Chatbots In The Enterprise
Generic AI chatbots often fall short in high–stakes business environments, where accuracy, context–awareness, and real–time adaptability are critical. Here are three major limitations enterprises face when relying on off–the–shelf LLMs.
-
Hallucinations Undermine Trust and Compliance
Most large language models generate responses based on probability rather than verified facts. In a 2024 Stanford study, generic AI chatbots were shown to fabricate citations 27% of the time.
Real–World Risk: In a high–profile case, a New York City lawyer submitted a legal brief with fake AI–generated citations – damaging credibility and drawing court sanctions.In regulated industries, a single hallucinated response can trigger legal, financial, or reputational fallout.
-
Static Knowledge Bases Can't Keep Up
Internal policies, SKUs, procedures, and pricing change constantly. Traditional chatbots require costly manual retraining to reflect those updates.
Pain Point: "Our chatbot still answers with last quarter's policies because updates take weeks to implement." —Enterprise IT ManagerThese delays frustrate users and place a heavy burden on content and IT teams trying to keep up.
-
Search Fatigue Leads to Lost Productivity
Employees waste hours digging through SharePoint, Confluence, and internal documentation to find what they need. As a result, support tickets stack up and productivity suffers.
Cost Per Interaction:
$7.60 — average cost per support ticket in 2023 (HDI: State of Tech Support)
Down from $16 in 2015, but still a major resource drain.
What Makes Custom RAG Solutions Different?
Unlike generic chatbots, custom RAG solutions are built on your business data, workflows, and priorities – delivering accurate, context–aware answers you can trust. They combine retrieval precision with generative power to create AI solution that actually knows your organization.
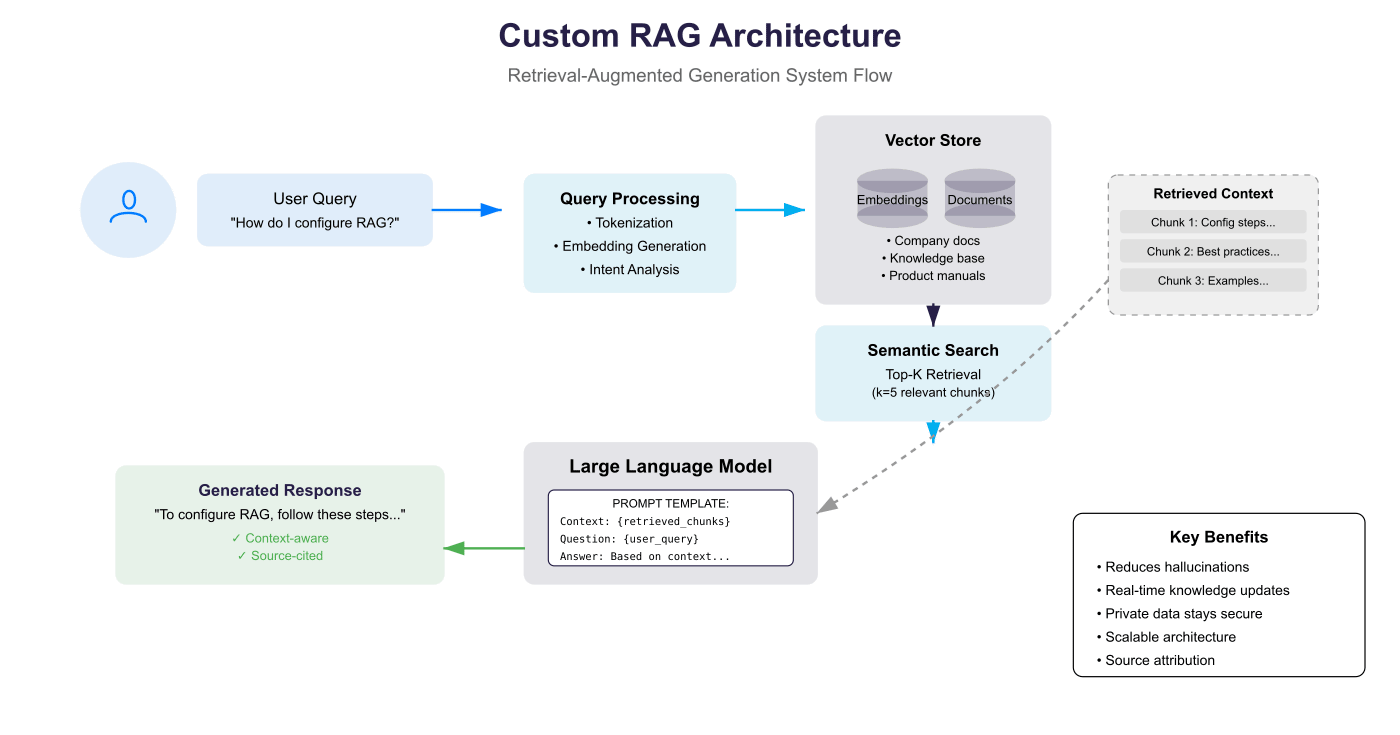
- User submits a natural language query: "How do I configure RAG?"
- Query enters the system through the user interface
- Tokenization - Break query into processable tokens
- Embedding Generation - Convert query into vector representation
- Intent Analysis - Understand the query's purpose and context
Processed query sent to Vector Store containing:
- Company documents
- Knowledge base articles
- Product manuals
4. Semantic Search & Retrieval
- Semantic Search executes similarity matching
- Top–K Retrieval selects most relevant chunks (k=5)
- Returns best–matching document segments
Retrieved chunks compiled into context:
- Chunk 1: Configuration steps
- Chunk 2: Best practices
- Chunk 3: Examples
6. LLM Generation Phase
Prompt Template constructed:
- Context: {retrieved_chunks}
- Question: {user_query}
- Answer: Based on context...
7. Response Delivery
Final response returned to user
Response characteristics:
- Context–aware (based on company data)
- Source–cited (traceable to documents)
Key System Benefits
- Reduces hallucinations through grounded generation
- Enables real-time knowledge updates
- Keeps private data secure within infrastructure
- Provides scalable architecture
- Maintains source attribution for trust
Step-by-Step Framework for Deploying Custom RAG Solutions
1. Opportunity Mapping
Identify high–traffic knowledge domains — support, compliance, field manuals — where answer speed and accuracy translate directly into revenue protection or cost savings.
2. Data Curation and Chunking
Break long manuals or wiki pages into 300–token chunks, embed with an open–source model like all–MiniLM–L6–v2, and store in a vector database. Mitigate PII exposure via automated redaction pipelines.
3. Retrieval Tuning
Blend semantic search with Okapi BM25 (a ranking algorithm used in information retrieval to determine the relevance of documents to a search query) to balance precision and recall. Continuous A/B testing adjusts similarity thresholds, minimizing irrelevant context.
4. Prompt Orchestration
Create a system prompt that:
- Summarizes the company persona and tone.
- Includes retrieved passages as fenced context.
- Instructs the model to decline outside scope.
5. Governance and Monitoring
Implement real–time feedback loops: thumbs–up/down, flagged answers, automated red–team prompts, and scheduled re–embedding of updated docs.
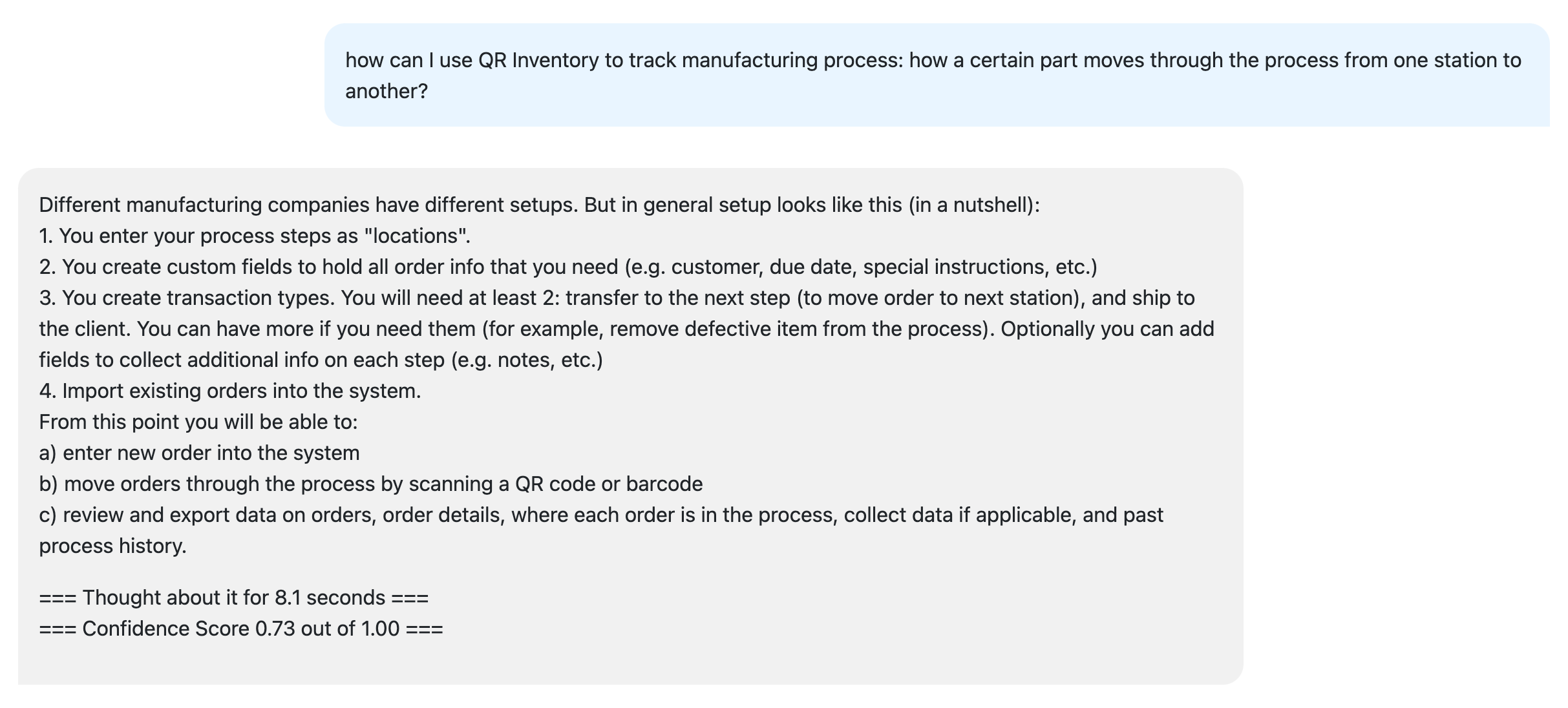
6. Confidence Score
We also like to give user a Confidence Score reading as a gauge of the answer dependability, as shown on a screenshot below:
ROI Considerations
| Metric | Before RAG | After RAG | Time to Realize |
|---|---|---|---|
| First–contact resolution | 64 % | 88 % | 90 days |
| Avg. ticket cost | $7.60 | $3.20 | 120 days |
| Content update lag | 2–4 weeks | < 24 h | Immediate |
A SaaS provider slashed $1.3 M annual support spend after rolling out a Custom RAG Solution across three languages—payback in eight months.
Implementation Timeline and Resource Requirements
| Phase | Duration | Key Activities | Stakeholders |
|---|---|---|---|
| Discovery | 2 weeks | Use–case selection, KPI definition | Product, Support, IT |
| Data Prep | 3 weeks | Content audit, chunking, embedding | Data Eng, SMEs |
| Build & Integrate | 4 weeks | Vector DB, prompt design, API hooks | ML Eng, DevOps |
| Pilot & Tuning | 3 weeks | A/B tests, feedback loops | Support, QA |
| Full Rollout | 2 weeks | Localization, training, dashboards | Change Mgmt |
Common Pitfalls and How to Avoid Them
- Over–chunking: 50–token snippets increase noise. Stick to 200–400 tokens.
- Stale embeddings: Schedule nightly jobs or webhooks for docs that change.
- No guardrails: Deploy content–safety filters and scope–decline prompts.
- Hidden costs: Track vector storage and inference fees from day one.
Future Trends and Strategic Considerations
- Hybrid Search: Combining graph databases with vectors for relationship–aware answers.
- Multimodal RAG: Images and diagrams retrieved alongside text for richer field–service instructions.
- Personalized RAG: Context filtered by user role, location, or entitlement.
